Información, probabilidad, bits, el juego de las preguntas y las entropías.
Por Lorenzo Hernández • 26 Mar, 2014 • Sección: Hablar de CienciaSiempre que queremos entender un concepto es útil partir de la idea cotidiana que tenemos del mismo para ir descartando posibilidades e ir afinando la definición. Ocurre cuando queremos hablar en física de conceptos como la energía, el calor o el trabajo, palabras muy usadas en nuestra vida cotidiana pero que tienen un significado distinto en física. Una de esas palabras que usamos muy a menudo es «información». Es una palabra muy usada porque vivimos en la era de la información: se transmite la información de manera rápida, la información se guarda en los ordenadores, etc.
En el contexto habitual la información la consideramos como mensajes que nos llegan, ya sea por vídeo, imagen, texto o las tres mezcladas, que nos son útiles. Pero el término de información suele ser ambiguo, impreciso y subjetivo, y cambia según el contexto. De hecho, la misma «información» tendrá diferentes significados, efectos y valores en personas diferentes. Si dos personas invierten en bolsa, ambas tendrán reacciones diferentes al leer la noticia que determinados valores han subido o han bajado. Y a otros que no inviertan le dejarán indiferente.
La definición más precisa de información procede de la obra de Claude Shannon, quien en los años cuarenta llevó a cabo un análisis cuantitativo preciso de la capacidad de transmisión de la información de un canal de comunicación. Shannon desarrolló un cuerpo matemático cuantitativo, preciso, objetivo y útil a partir de un concepto subjetivo e impreciso. Pero esto lo veremos más adelante.
Idea intuitiva de información.

Para ir teniendo una idea intuitiva sobre la información e ir afinando su definición, antes de llegar a su definición matemática, podemos preguntarnos en qué situaciones obtenemos más información o si ciertos sucesos nos proporcionan más información que otros. Digámoslo de otro modo: ¿cuándo una noticia tiene más interés informativo? Será aquella que menos nos esperemos que ocurra, es decir, que menos probable sea. Por ejemplo, la noticia «Montoro baja los impuestos» sería un notición ya que la probabilidad que ocurra es baja (muy baja). Nos quedaríamos igual (¡o más!) de sorprendidos si al tirar 6 dados nos saliera 6 seises o si se estrellara un avión en el ayuntamiento de nuestra ciudad.
Pero un hecho improbable, además de sorprendernos, nos aporta más información sobre un fenómeno o sobre cómo funciona el mundo. Pongamos el siguiente ejemplo:
El servicio meteorológico emite los siguiente mensajes:
- Mensaje 1: día muy frío y nublado.
- Mensaje 2: día muy frío y soleado.
- Mensaje 3: día frío y nublado.
- Mensaje 4: día templado y soleado.
¿Cuál nos da más información sobre cómo funciona el tiempo atmosférico?
Sería el mensaje 2 ya que es lo menos habitual. Es normal relacionar el frío con un día nublado y un día soleado con un templado, pero es menos habitual que un día soleado sea muy frío. Esta situación nos da pie a estudiar otros aspectos del clima que afectan a las temperaturas, es decir, nos proporciona más información.
Otro ejemplo sería el comportamiento humano. Si estudiamos el comportamiento humano nos dará muy poca información un grupo de individuos que se comporten como lo esperado, lo más probable: madrugan, van a atrabajar, comen a su hora. Lo que nos puede dar más información sobre el comportamiento humano son esos comportamientos menos probables: que cuando lleguen a casa se tiren por la ventana. Este suceso poco probable nos da pie a estudiar por qué ha ocurrido y conocer mejor cómo funciona nuestro cerebro o la sociedad.
En ciencia ocurre algo parecido. Un experimento que nos da resultados inesperados, que eran poco probables según al teoría vigente, nos hace avanzar en nuestro entendimiento del mundo más que todos aquellos que han dado los resultados esperados. Imaginemos que estoy estudiando la dilatación de los metales al aumentar su temperatura, que he hecho cien pruebas con metales diferentes y todos se han dilatado, y en el experimento 101 hay uno que se contrae. Es un suceso poco probable según la experiencia por lo que nos dará más información sobre cómo se comportan realmente los metales y tendré que desarrollar una teoría más completa que explique también este caso.
No sé si a los periodistas le dan esta definición intuitiva de información pero así podemos saber que «Unos aviones se estrellan contra las Torres Gemelas» sí es noticia, ya que es muy poco probable, mientras que «Sergio Ramos se cambia de peinado» no es noticia, ya que es algo común. Aunque los medios de comunicación, supongo, se guían por otros criterios.

Esta breve introducción nos permite relacionar la información con la probabilidad. Esta relación no es nueva, ya los antiguos griegos relacionaron la probabilidad de que ocurra algo con la cantidad de información que nos aporta. Así pues, tenemos que tener ciertas nociones básica de probabilidad para entender el concepto de información.
Resumen: La información está relacionada de alguna manera con la probabilidad de que ocurra un suceso.
Probabilidad.

La probabilidad es la rama de las matemáticas que estudia el azar, es decir, los fenómenos aleatorios, que no están determinados. Tiene usos en todos los campos de la ciencia, desde la física y la química hasta la biología y la sociología, la economía y la psicología; es resumen, en todos los aspectos de nuestras vidas. Para entender el concepto matemático de información hay que sabe un poco de probabilidad. Para ello hay que conocer algunos conceptos:
Espacio muestral: Es el conjunto de todos los resultados posibles de un experimento específico bien definido.
Probabilidad: A cada suceso le asignamos un número que llamamos probabilidad de ese suceso, con las siguientes propiedades:
- La probabilidad de cada suceso es un número entre 0 y 1. Si hablamos en tanto por ciento sería del 0% al 100%.
- La probabilidad de un suceso seguro es 1 (del 100%).
Parémonos un momento y pongamos dos ejemplos típicos:
Un experimento puede ser tirar una moneda al aire. Si tiramos una moneda que no esté trucada puede ocurrir que salga cara o cruz (despreciemos el canto). Matemáticamente, según la regla de Laplace, la probabilidad se calcula de la siguiente manera:

En el caso de la moneda sólo puede salir un resultado de dos posibles, por lo que la probabilidad es de ½ o del 50%. Del mismo modo, la probabilidad de sacar un 6 en un dado es de 1/6. Esto quiere decir, que si hago un largo número de tiradas, de media una de cada seis veces me saldrá un 6; o si tiro mil veces una moneda hay muchas posibilidades de que 500 sean cara y 500 cruz. Aunque se puede obtener 590 caras y 410 cruces. En probabilidad, cuando un suceso es seguro que va a ocurrir, que va a ocurrir al 100%, decimos que tiene valor 1 y si es imposible, 0% de que ocurra, el 0. En resto de sucesos estará comprendidos entre 0 y 1. En los ejemplos propuestos, la probabilidad de que me salga cara será 0.5 y que me salga un 6 será 0.1666…

Valor promedio.
Otro concepto importante es el valor promedio. Sabemos que la media es la suma de todos los resultados entre el número de resultados.
Imagina que tenemos un dado de seis caras, donde en tres de las caras tenemos al valor 2 y en las otras tres el valor 4. Es decir, que los resultados posibles son 2 y 4. Si calculo la media de los resultados que obtengo, si hago muchas tiradas el valor promedio se acercará a la media aritmética:


Imagina ahora que tenemos un dado de tres caras, donde en dos de ellas tengo el valor 4 y en la otra el valor 2. La probabilidad de obtener un 2 es de 1/3 y de sacar un 4 de 2/3. Ahora, si hacemos muchas tiradas, la media o el valor promedio no se acerca a 3 sino a 3,333… Es lógico, ya que hay un número menor que 3 (un dos) y dos mayor que 3 (dos cuatros).
Para calcular el valor promedio debemos sumar el producto de cada valor por su probabilidad, según la siguiente ecuación:

En el caso del dado:

En estos casos tenemos que creer que la probabilidad de salir una cara del dado u otra es la misma. Esta creencia proviene por la simetría del dado. Los caras de los dados son iguales por lo que tienen la misma probabilidad.
Código binario y bits.
El código binario es un lenguaje que se basa en representar cualquier información en ceros y unos. Así funcionan los ordenadores o cualquier dispositivo electrónico. Cuando en un ordenador pasa corriente se considera un 1 y cuando no pasa corriente se considera un 0. Es como una especie de código Morse. Con ceros y unos es posible escribir todos los números, palabras, representar imágenes o vídeos. Para entender de manera sencilla en qué consiste te recomiendo que veas el siguiente vídeo.
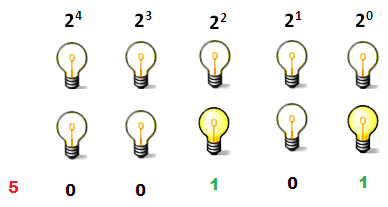
Cada 0 y cada 1 es un Bit (Binary digit) y es la unidad mínima de información.
Se puede imaginar un bit como una bombilla que puede estar en uno de los siguientes dos estados:

- Si consideramos que el estado «apagada» es un 0 y «encendida» es un 1, con una bombilla tendríamos dos estados posibles: 1 y 0.
- Con dos bombillas tendríamos 4 : 00, 10, 01 y 11.
- Con tres bombillas tendríamos 8 estados: 000, 100, 010, 001, 110, 011, 101 y 111.
- Y así sucesivamente.
Si ahora asignamos a cada bombilla un valor, podemos escribir los números naturales en forma de ceros y unos. Veamos un ejemplo:
A cada bombilla se le asigna el valor doble que la anterior. Así, tenemos que la primera vale 1, la segunda 2…hasta la quinta que tiene un valor de 16. Para representar un número solamente tendremos que encender la bombilla o bombillas correspondientes que sumen dicho número.

De esta manera,
- el 0 en binario es 0;
- El 1 es 1;
- el 2 es 10;
- y el 5 es 101.
Realmente, lo que se está haciendo es multiplicar el valor de la bombilla (0 ó 1) por una potencia de 2. Si tomamos como ejemplo el 5.

Pero no hay que hacer el «juego» de las bombillas cada vez que quiera escribir un número en código binario. Si cualquier número lo voy dividiendo entre dos y me quedo con los restos lo puedo expresar en código binario. Por ejemplo:

Esto se puede hacer también para las letras y para las imágenes (ver el vídeo anteriormente recomendado).
Como he dicho antes, cada 0 y 1 son un bit, la unidad mínima de información. Para escribir el 5 necesitaría 3 bits (101) y el 26 se escribe con 5 bits (01011). Para calcular de manera directa el número de bits podemos usar el logaritmo en base 2 o logaritmo binario. Se usa logaritmo en base dos porque sólo hay dos estados posibles.

Esto determina a que valor y hay que elevar 2 para obtener x
- Si x = 1, y = 0; ya que 2 elevado a 0 es 1.
- Si x = 2, y =1.
- Si x = 5; y = 2.321928
- Si x = 256; y = 8
Como nos indica los ceros y unos que necesitamos nos está diciendo los bits. Para representar el 256 necesito 8 bits.
Concepto matemático de información.
Hemos dicho que un suceso menos probable nos aporta más información que uno más probable, por lo que la información debe ser inversamente proporcional a la probabilidad. Es decir, a menos probabilidad más información. Pero debe de cumplir otra propiedad. Supongamos que estamos considerando la información de dos sucesos independientes, es decir, que uno no depende del otro. Si tiro un dado y obtengo un 6 y tiro otro dado y obtengo otro 6, ambos sucesos son independientes ya que el resultado del segundo dado no está influenciado por el primero. La probabilidad de que ocurra esto se calcula multiplicando ambas probabilidades:

¿Qué podemos decir de la cantidad de información contenida en estos dos sucesos? Pues si queremos que nos salga un 6 y nos sale nos sorprendemos, aunque no mucho, pero si nos sale otro 6 a continuación la sorpresa es mayor. Así, la información total contenida en estos dos acontecimientos debe ser la suma de ambas. En consecuencia, la fórmula de la información tiene que ser una función tal que la información que la información del producto de dos probabilidades sea igual a la suma de la información contenida en los acontecimientos individuales. Hay solamente una función así, y es la función logarítmica o el logaritmo (log).
Así, la definición moderna y matemática de la información de un acontecimiento es proporcional al logaritmo de la inversa de la probabilidad.

Si nos interesa obtener el resultado en base 2 usaremos:

Según esta fórmula, cuanto menor sea la probabilidad de que ocurra mayor será la información que nos de. Y si hay un 100% de que ocurra, es decir que ocurre siempre, la información será 0. Y si la probabilidad de que ocurra es 0, la información sería infinito. Es algo que no ocurre, ya que la probabilidad de que ocurra es 0. Las demás situaciones estarán entre 0 y 1.
Por ejemplo, si tengo un moneda con dos caras la probabilidad de que salga cara es 1 por lo que la información que obtengo del resultado es 0, que no puede ocurrir otra cosa (obviemos otra vez el canto).
Volvamos al juego de los dados. ¿Qué información asociada a las siguientes probabilidades es mayor, la que tiene la probabilidad de 1/4 o la de 2/4?


El valor promedio de la información.
Al igual que el valor promedio de la probabilidad podemos calcular el valor promedio de la información. El promedio será la suma de la información por la probabilidad de cada suceso.

Pongamos un ejemplo: Si lanzamos un moneda los sucesos serán (cara, cruz) y la probabilidad de cada uno será 1/2. Por tanto, el promedio de la información será:

No siempre que tenemos dos opciones podemos tener una información de 1 bit. Veamos otro ejemplo:
Adivinar el género de las personas que están viendo el fútbol en un bar.
Entramos a un bar con los ojos cerrados y cogemos una persona al azar. ¿Qué probabilidad hay de que sea hombre o mujer? Si de cada 10 personas que hay en un bar 9 son hombres la probabilidad de que se hombre es 9/10 y mujer 1/10.
La información asociada a suceso hombre será 0,15 bits.
Y si es mujer 32 bits.
Y el promedia es 0,47 bit
En resumen:
- Información al lanzar una moneda con dos caras (suceso con la misma probabilidad) : 1 bit
- Información de dos sucesos con distinta probabilidad (ejemplos del hombre y la mujer): 0,47 bits.
- Información de un suceso que seguro que ocurre (moneda con dos caras): 0 bits.
El juego de las preguntas.
Antes se seguir te animo a jugar. Imagina que tengo una bolsa con ocho bolas que tienen un valor del 1 al 8. Supongamos que los probabilidad de que salga cada bola (p1, p2, p3…p8) es la misma. Saco una de esas bolas y tú tienes que adivinar qué bola he sacado haciendo preguntas que tengan por respuesta un SI o un NO. Podrías seguir dos estrategias, una más inteligente que otra.
La primera, y más burda, es preguntarme:
- ¿Te ha salido el 1? No.
- ¿Y el 5? No
- ¿Y el 3? No
- Etc.
Con esta estrategia puede que lo adivines a la primera o tendrás que hacer hasta 8 preguntas para adivinarlo. Si lo haces muchas veces el promedio de preguntas será 4.
La otra estrategia es más inteligente, ya que baja el promedio de preguntas. Esta estrategia se llama Búsqueda binaria.
Estrategia Binaria.
Esta estrategia consiste en ir partiendo en 2. Las posibilidades son las siguientes:

De esta manera en 3 preguntas podemos llegar a adivinarlo. Si lo hacemos muchas veces siempre lo adivinaremos en 3 preguntas por lo que hemos disminuido el promedio de 4 a 3 preguntas.
Esta es la mejor manera de búsqueda si los sucesos que tienen la misma probabilidad. pero si no lo son hay estrategias que me disminuyen el promedio de preguntas.
Estrategia Jerárquica.
Supongamos que la probabilidad de cada bola ya no es la misma sino son la siguientes:
- Bola 1: 0,35
- Bola 2: 0,25
- Bola 3: 0,12
- Bola 4: 0,10
- Bola 5: 0,08
- Bola 6: 0,06
- Bola 7: 0,03
- Bola 8: 0,01
Lo inteligente ahora es preguntar primero por el que tiene más probabilidades de que salga:
- ¿Es 1? Sí.
- ¿Es 1? No. ¿Es 2? Sí.
- Etc.
El promedio de preguntas será:
1·0,35 + 2·0,25+ 3·0,12 + 4·0,10 + 5·0,08 + 6·0,06 + 7·0,03 = 2,83.
Baja el número de preguntas promedio.
Pero con las mismas probabilidades hay otra estrategia mejor aún.
Estrategia de Shannon-Fado.
Consiste en hacer preguntas donde cada partición tenga las mismas probabilidades o las más parecidas posible.
- ¿Es 1, 3 o 7?
Se pregunta esto porque la suma de estas probabilidades es del 0,5 (50%).
Si la respuesta es Sí, dividimos la pregunta con la condición de que la probabilidades sean parecidas:
En este caso sería:
- ¿Es 3 o 7? o ¿Es 1?
Ya que p3 y p7 suman 0,15 y p1 0,35. Es lo más equilibrado.
Si seguimos esta estrategia bajamos el promedio de preguntas a 2,65.
Pero hay una estrategia aún mejor y es realizar al algoritmo de Hoffman. Consiste en construir un árbol de abajo hacia arriba de tal modo que abajo se sitúan las opciones con menos probabilidades. Estas probabilidades se van sumando y subiendo de nivel, situándose en un nivel equivalente a otras probabilidades superiores. Para no extenderme demasiado este algoritmo se explicará más detenidamente más adelante aplicándolo a la compresión de datos. Pero, en este ejemplo concreto, con esta estrategia o algoritmo se reduce el promedio de preguntas a 2,54.
Lo importante de esta estrategia es que Huffman demostró matemáticamente que no hay otro algoritmo por el que se consigan menos preguntas.
Entropía de información.
La entropía de la información es la suma de la información de cada suceso por la probabilidad de que ocurra, es decir, el promedio de la información. Fue definida por Shannon y su fórmula matemática es:

Lo curioso y sorprendente de esto es que si hacemos este cálculo, para el ejemplo que hemos supuesto, nos sale 2,48, que es el resultado óptimo del algoritmo de Huffman. Esto quiere decir que en este caso no hay manera de resolver este problema con un promedio de menos de 2,48 preguntas.
Este número indicaría el mínimo que un canal de comunicación puede transmitir.
Diferencia entre estrategia de Hoffman y Entropía.
El algoritmo de Huffman es el mínimo del promedio de preguntas (2,54 para este caso) para unas probabilidades concretas. En nuestro ejemplo, 2,54 es el promedio mínimo de preguntas para este caso. Pero si proponemos otras probabilidades es posible bajar el promedio de preguntas. La Entropía es una limitación del número mínimo de preguntas promedio. Es decir, combinando de todas las maneras posibles las probabilidades, para este caso no puedo mejorar el número de 2,48.
Hoffman y compresión de datos.
El algoritmo de Hoffman es el que se usa para comprimir datos. Veámoslo más detenidamente con un ejemplo.
Al igual que números, se pueden escribir palabras en código binario. Solamente hay que asignar a cada letra un número (obviemos las mayúsculas):
a=1, b=2, c=3…z= 27.
Así, «abc» sería como escribir «123» que en binario es «11011» (recordemos las bombillas). Tomemos como ejemplo (que va a ser el ejemplo del vídeo) la palabra «Laptop». Si le asignamos el número correspondiente a cada letra obtendremos «12(L)a(1)16(p)20(t)15(o)» que en código binario es: 1100-1-10000-10100-1111. Esto serían un total de 19 bits. Pero esta no es la manera más comprimida posible para escribir dicha palabra en código binario. Para ello hay que usar el algoritmo de Hoffman. Veamos como se hace en el siguiente vídeo:
Como se comprueba en el vídeo la palabra se puede escribir con 12 bits (11011110000110) por lo que se comprime 7 bits.
Resumen: La información se define matemáticamente como
Entropía termodinámica.
La Entropía termodinámica, que se denomina con la letra S, es una medida del desorden de un sistema. A mayor Entropía, mayor desorden. Según la segunda ley de la termodinámica, cualquier sistema aislado, que no intercambia materia ni energía con el exterior, tiende a la máxima Entropía, es decir, al máximo desorden. En muchas ocasiones, se suele poner el ejemplo del dormitorio, aunque no es correcto del todo porque la segunda ley se aplica a sistemas aislados, y nosotros interactuamos con el dormitorio. Imagina un dormitorio perfectamente ordenado, con la ropa ordenada por colores, los libros en orden numérico y cada zapato en su caja correspondiente. Poco a poco, conforme pasa la semana, el dormitorio se irá desordenando a no ser que gaste energía para ordenarlo. Esto ocurre por una sencilla razón. Sólo hay una única manera de que los zapatos estén ordenados, metidos en su caja, e infinitas maneras de que no estén en su caja y que estén desordenados. Lo mismo ocurre con la ropa. Sólo hay una forma de que esté ordenada por colores y muchas maneras de estar desordenada. Por tanto, también es cuestión de probabilidad.
Juguemos otra vez a los dados para entenderlo más profundamente y posteriormente pondré un ejemplo físico.
Con 1 dado.
Empecemos el juego con un dado. Si calculamos la probabilidad de que salga un resultado es 1/6, teniendo en cuenta que todos los resultados son igualmente probables. Esto ya lo sabíamos.
Con 2 dados.
Con dos dados el juego consiste en apostar cuánto suman los dos dados. Es decir, si sale 1 y 3 la suma será 4. ¿Cuál es la suma más probable? Los resultados posibles son los siguientes:
 La probabilidad de que salga una pareja de resultados es 1/6 por 1/6, es decir 1/36.
La probabilidad de que salga una pareja de resultados es 1/6 por 1/6, es decir 1/36.
Los resultados posibles de la suma de los dos dados son:
2, 3, 4, 5, 6, 7, 8, 9, 10, 11 y 12.
Los resultados que dan una cierta suma son los siguientes:

Podemos observar que hay 36 posibles resultados (6 elevado a 2) y la suma más probable es 7, mientras que la menos probable es el 2 y el 12. Para sumar 7 tenemos 6 posibles resultados. Por tanto, la probabilidad de sumar 7 es de 7/36.
Con tres dados.
Podemos hacer lo mismo con tres dados. Con tres dados tenemos 216 (6 elevado a 3) combinaciones posibles, la sumas posibles van del 3 al 18, las sumas más probables son 10 y 11 y la obtendríamos con 27 posibles resultados. Por tanto, la probabilidad de obtener una suma de 10 u 11 es de 27/216.
Con muchos dados.
Podemos seguir con cuatro, con cinco, con cien, con mil o con un millón de dados y calcular todas las posibles combinaciones y sumas. Lo que podemos apreciar es que conforme aumentamos el número de dados hay ciertas sumas que son más probables que otras y disminuye mucho la probabilidad de que salgas otras sumas. Por ejemplo, si tenemos 1000 dados la probabilidad de que la suma sea 1000 es muy, muy pequeña, ya que todos todos los dados tienen que salir 1, algo muy improbable. Es decir, hay sumas o configuraciones que son más probables que otras.
Entropía en un sistema físico.
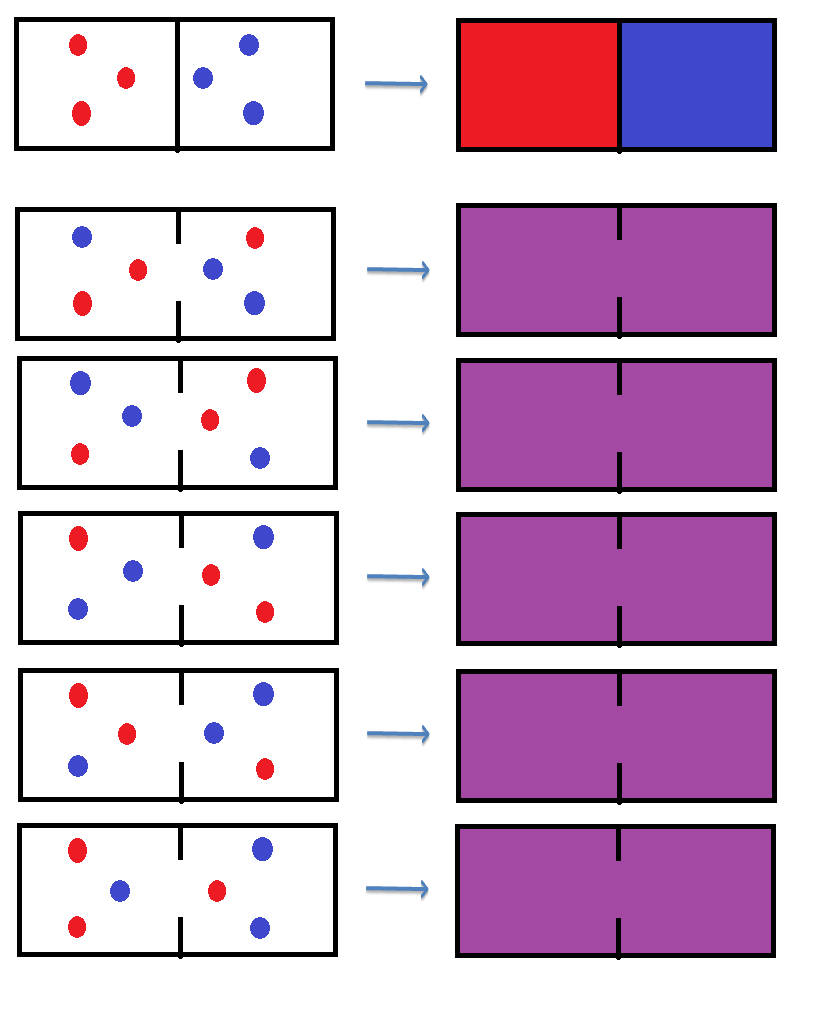
Apliquemos ahora este principio a un sistema físico simple. Imaginemos una urna separada por una pared donde en cada parte hay un tinte. Uno rojo (R) y otro azul (A). Imaginemos que el tinte está formado por dos partículas. Si se juntan las urnas veremos que al cabo de un tiempo se mezclan y observaremos que se forma un tinte morado (M), la mezcla de azul y rojo. Para simplificar despreciemos las intensidades intermedias, solamente nos interesa si todas las azules y rojas están en su lado o si no lo están. En cuanto una se desplace al otro lado consideraremos el estado M.
Con 2 partículas:

La pregunta que viene ahora es: ¿Es posible observar que el sistema vuelve al estado de R-A una vez que está en el estado M? En la situación anterior vemos que hay 1/3 de probabilidades de que esté R-A y 2/3 de que esté M. Por tanto, hay 1 posibilidad de 3 de que las partículas azules coincidan en la derecha y las rojas en la izquierda.
Si aumentamos el número de partículas a 3:

También es posible que la rojas se sitúan a la derecha y la azules a la izquierda, pero obviemos esta situación.
Observamos que conforme aumentamos el número de partículas la probabilidad de que coincidan las azules a la derecha y las rojas a la izquierda disminuye. Si tuviéramos millones y millones, que es lo ocurre en realidad, la probabilidad sería ínfimamente pequeña, aunque existe. Es por esto que nunca vemos que una vez mezclados los tintes el sistema sólo vuelve al estado R-A. Es tan improbable que no ocurre.
Si consideramos el sistema R-A como ordenado y M como desordenado llegamos a la conclusión que es más probable que este sistema esté desordenado ya que hay múltiples formas de que esté desordenado (M) y sólo una que esté ordenado (R-A). Es como el ejemplo que puse anteriormente del dormitorio.
Relación entre entropía de la información y entropía termodinámica.
Aunque Rudolf Clausius acuñó el término «entropía» en 1865, fue Ludwig Boltzmann quien un año después reconoció que podía interpretarse en términos de desorden. Por tanto, nos referimos a esta concepción de la entropía termodinámica como «entropía de Boltzmann». Un segundo uso del término «entropía» se ha aplicado extensamente a la evaluación de la información, y por razones relacionadas. A finales de los años cuarenta, el matemático Claude Shannon, de los laboratorios Bell, demostró que la medida más relevante de la cantidad de información que puede transportarse en un medio de comunicación dado (como una página impresa o una transmisión de radio) es análoga a la entropía estadística (entropía de Boltzmann). Según el análisis de Shannon, la cantidad de información transmitida en cualquier punto equivale a la improbabilidad de recibir una señal dada, determinada respecto de las probabilidades de todas las señales que podrían haberse enviado. Puesto que esta medida de las opciones de señal es matemáticamente análoga a la medida de las opciones físicas en entropía termodinámica, Shannon también llamó a esta medida la «entropía» de la fuente emisora. Nos referimos a ella como «entropía de Shannon».
Como vemos, ambas entropías están relacionadas con la probabilidad. Cuando hablamos de «información» dijimos que a menor probabilidad mayor información. En el caso de la entropía termondinámica, tomando el ejemplo del tinte, nos sorprendería mucho ver que espontáneamente vuelve al estado R-A ya que la probabilidad es ínfimamente pequeña. Si ocurriera esto poco probable la información que nos proporcionaría dicho suceso sería muy eleveda. Sin embargo, si lo vemos en el estado M, máximo desorden, no nos información ya que la probabilidad es muy elevada.
La información en el ejemplo del tinte con 3 partículas:
La probabilidad del suceso R-A es de 1/7 y el de morado es de 6/7. Por tanto, la información en cada caso será:


Comprobamos que la información que nos daría el suceso R-A sería casi 13 veces mayor que el estado M.
Si consideramos el estado de equilibrio, el estado M, vemos que todas las probabilidades son iguales y nos proporciona un mínimo de información. Así, el estado M es el más probable por lo que nos proporciona un mínimo de información. Mientras que el R-A es el menso probable, por lo que nos proporciona mayor información.
Podemos deducir que a mayor organización de un sistema, mayor es su contenido de información ya que su probabilidad es baja, y viceversa.
Fuentes consultadas:
Conferencia: Teoría de la información. Breve introducción práctica. Javier García. http://www.youtube.com/watch?v=XD04KAFqlTY
Naturaleza incompleta. Cómo la mente emergió de la materia. Metatemas 127, 2013.
Descodificando al realidad. El universo como información cuántica. Vlatko Vedral. 2011.
La entropía desvelada. Arieh Ben-Naim. M. Metatemas 118. 2011
Esta entrada participa en la Edición 5.2 del Carnaval de Matemáticascuyo anfitrión es Matesdedavid





{kind=link}
{kind=link}